На минувшей неделе на фондовом и технологическом рынке США произошло потрясение, какие случаются нечасто. Акции американской технологической компании «Nvidia» (она является разработчиком графических процессоров и систем на чипах) в понедельник, 27 января 2025 года, рухнули на 17,31%, а капитализация компании потеряла более $570 млрд.
Владельцы акций «Nvidia» также потеряли миллиарды долларов. Приводившиеся суммы убытка 500 самых богатых людей мира приводились разные, но наиболее часто встречалась такая: $108 млрд.
Обвал акций и финансовые потери (впрочем, о потерях поговорим ниже), как гласили многочисленные публикации и теле-сюжеты, были спровоцированы успешным запуском китайского чат-бота DeepSeek-R1, который, дескать, едва ли не по всем позициям (прежде всего, по показателям цена-качество-производительность) обошли лучшие наработки в развитии искусственного интеллекта (ИИ) корпораций из США.
Информационный шум был настолько сильным и разнонаправленным, что даже те, кто пытался разобраться в том, что же, чёрт побери, на самом деле произошло, сделать это могли с большим трудом.
Редакция «Ригеля» тоже попыталась разобраться в том, что произошло. И вот к каким выводам мы пришли.
ЧТО УМЕЕТ DEEPSEEK?
Не будем углубляться в технические детали — этого добра на просторах Сети навалом. Попытаемся объяснить суть простым языком.

DeepSeek — китайская нейросеть, представленная в виде чат-бота с искусственным интеллектом. Нейросеть работает по тому же принципу, что её аналоги — по запросу пользователя так же, как ChatGPT (разработка компании OptnAI), Google Gemini и GigaChat (разработан в недрах Сбера) он выдаёт информацию на нужную тему.
Такая нейросеть представляет собой типичный чат-бот с окном чата для ввода текстовых запросов и кнопкой прикрепления дополнительных файлов (фото или документ).
Среди основных, наиболее популярных опций нейросетей, можно отметить следующие:
- ответы на вопросы;
- помощь с учебой;
- написание и перевод текстов;
- выдача советов;
- писк информации;
- решение креативных задач и просто развлечение.
Грубо говоря, с точки зрения взаимодействия с пользователем нейросеть DeepSeek не предлагает ничего нового. Ну, или почти ничего.
Компания DeepSeek была основана в 2023 году Лян Вэньфэном, главой хедж-фонда High-Flyer, занимающегося количественными инвестициями на основе ИИ. Компания разрабатывает модели ИИ с открытым исходным кодом и что означает, что сообщество разработчиков может проверять и улучшать программное обеспечение.

DEEPSEEK: ЭТАПЫ НЕДОЛГОГО, НО ВПЕЧАТЛЯЮЩЕГО ПУТИ
За успехами DeepSeek пристально следили многие конкурирующие и прочие структуры (в том числе — и в США) с момента выпуска его первой модели в 2023 году. Этапы развития компании DeepSeek вкратце выглядят так.
2 ноября 2023 года DeepSeek представила свою первую модель нейросети: DeepSeek Coder. Она была бесплатной (в том числе — для коммерческого использования), и имела полностью открытый исходный код.
В ноябре 2024 года DeepSeek представила следующую модель — R1 (DeepSeek-R1-Lite-Preview), разработанную, как заявляли её разработчики, для имитации человеческого мышления. Эта модель лежит в основе его мобильного приложения-чат-бота, которое вместе с веб-интерфейсом в январе стало всемирно известным как гораздо более дешёвая альтернатива OpenAI. Эта модель позволяла решать задачи, которые требовали логического вывода, математических рассуждений и решения проблем в условиях реального времени.
В январе 2025 года компания выпустила ещё более продвинутые, чем прежние версии: DeepSeek-R1 и DeepSeek-R1-Zero.
Что умеет делать эта версия нейросети? А вот что:
- создавать тексты разных объёмов и в разных жанрах;
- искать информацию в интернете;
- распознать один или несколько текстовых файлов общим объемом до 100 Мб;
- обрабатывать естественные языки;
- писать код, корректно форматировать его и решать сложные задачи по программированию;
- прогнозировать и моделировать.
Создание этой версии DeepSeek, как утверждали её создали, обошлось намного дешевле её американских аналогов.
Для создания модели компания использовала около 2 тыс. чипов NVIDIA H800 и потратила на это дело всего $5,6 млн. В США на такие разработки тратят десятки миллионов долларов и часто используют сотни тысяч процессоров. Например, OpenAI потратила на обучение GPT $78 млн.
Российские эксперты так вкратце описывают ключевые преимущества DeepSeek перед ChatGPT:
- стоимость: $2,18 у R1 против $60 за миллион токенов у o1 (то есть — у компании OpenAI);
- открытый исходный код и возможность локального запуска;
- доступ к актуальным данным через интернет;
- эффективная обработка технических и научных текстов;
- глубокий анализ документации и программного кода.
Вот тут-то и начала закручиваться история с падением акций на фондовом рынке.
ОБВАЛ НА РЫНКЕ — ЧЕМ ОН БЫЛ СПРОВОЦИРОВАН?
К 25 января мобильное приложение DeepSeek было загружено 1,6 млн. раз и заняло 1 место в магазинах приложений для iPhone в Австралии, Канаде, Китае, Сингапуре, США и Великобритании. Что как бы наносило удар по аналогичным продуктам американских разработчиков, прежде всего — компании «Nvidia».
Именно это обстоятельство и считают причиной обвала акций компании «Nvidia». Но так ли это было на самом деле? Скорее всего, нет.
В тех же Соединённых Штатах, как уже было сказано, за разработками DeepSeek внимательно наблюдали. С учётом того обстоятельства, что всё новые модели своей нейросети компания регулярно представляла с ноября 2023 года, для специалистов, безусловно, было понятно, в каком направлении идёт мысль китайских разработчиков.
Тогда почему произошёл обвал на фондовом рынке?
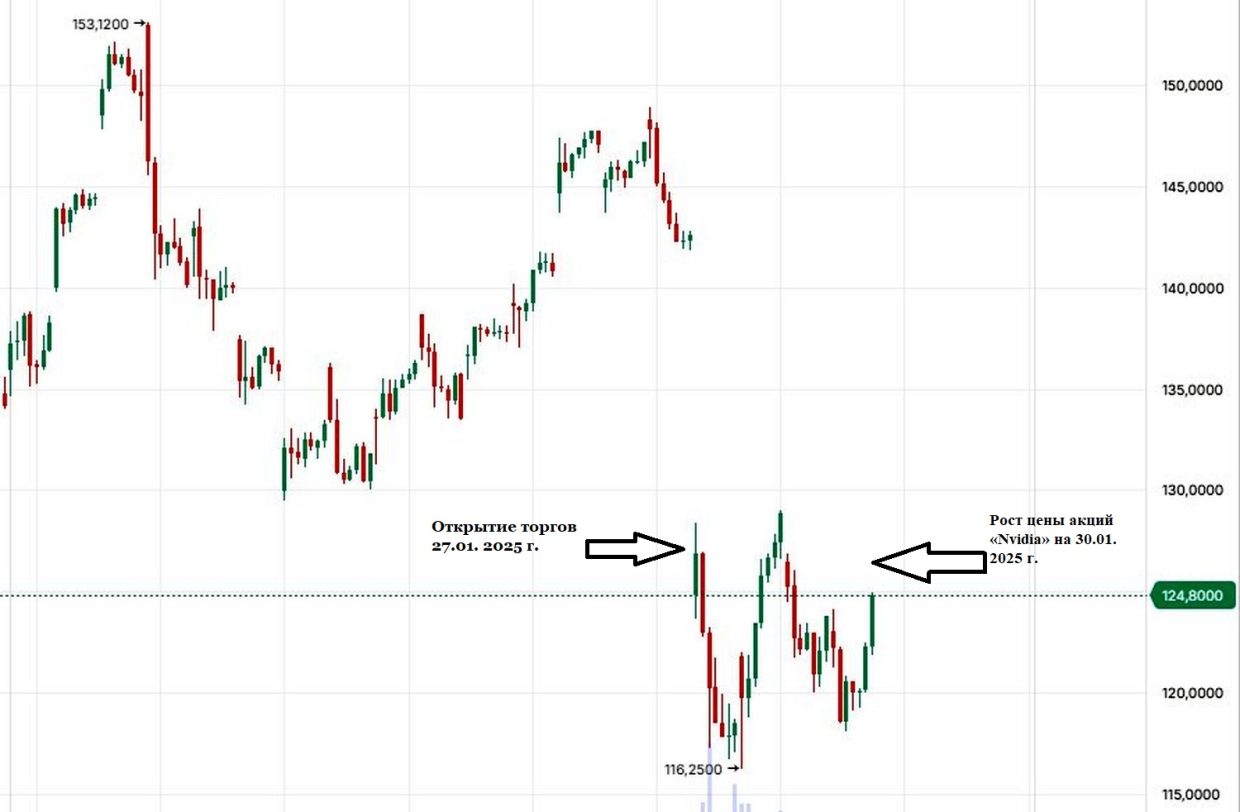
Ну, начнём с того, что это был не обвал. Падение цены акций «Nvidia» на $117-120 (минус 17-18%, порядка $18-20 за акцию) — сильная просадка, но не более того. Напомним, что на российском фондовом рынке в феврале-марте 2022 года, в связи с началом СВО, курсы акций ведущих компаний и фьючерсов рухнули на 45-50%. Многим тогда казалось, что это — конец, на восстановление уйдут многие годы. В итоге уже к первой половине 2024 года курсы не просто восстановились, но и превзошли уровень февраля 2022 года.
Когда в понедельник кто-то на просадке акций потерял миллиарды долларов, другие их начали зарабатывать. Уже во вторник, 28 января, акции «Nvidia» (кстати, не только этой компании) подросли на 9%.
При этом ещё накануне, в моменты пикового падения курсовой цены, акции «Nvidia» стали активно прикупать: розничные инвесторы приобрели акций компании на $562 млн., во вторник 28 января — ещё почти на $360 млн.
А сообщения о том, что 500 богатейших людей мира, дескать, потеряли на падении порядка $108 млрд. тоже, знаете ли, на умножить на 0,1: они потеряли в курсовой цене акций «Nvidia», которая завтра обязательно продолжит рост. Об этом свидетельствует нижеприводимый график (обратите внимание на фигуру так называемого «двойного дна», нечто типа латинской буквы W в правой нижней части графика, которая говорит об очень даже возможном росте цены акций «Nvidia» в ближайшее дни и недели).
К тому же, сколько эти 500 богатеев могло продать акции почти на пике их цены, а затем, на минимуме, заново (и в ещё большем количестве) прикупить, и сколько они на этом дополнительно заработали — об этом широкой публике обычно не сообщается.
Таким образом, не сообщение о большом количестве продаж чат-бота DeepSeek явилось причиной падения цены акций «Nvidia». Да это и не было падением в привычном смысле этого слова, а, скорее, перераспределением.
От участников рынка, слабо представляющих, что происходит и крайне подверженных эмоциональной реакции, акции (а, соответственно, и деньги) перетекли к трейдерам с железными нервами, владеющими (что главное!) инсайдерской информацией о том, как дела будут развиваться завтра.
События, скорее всего, происходили так. Желая дополнительно закупиться акциями «Nvidia» (причём, подешевле) ряд крупных трейдеров продаёт достаточно крупные пакеты акций компании. Как результат — котировки «Nvidia» начинают сильно проседать. Войдя в состояние паники, акции компании начинают скидывать те самые эмоционально податливые участники рынка, о которых было сказано ранее. Цена падает ещё ниже. После чего крупные игроки начинают выкупать подешевевшие акции «Nvidia».
А чтобы в Комиссии по ценным бумагам и биржам, в рамках антиинсайдерского законодательства, не стали задавать лишних вопросов (тем более — проводить расследование), с помощью СМИ разогнали шумиху о том, что дескать, этот как бы обвал спровоцировала информация о росте продаж нового чат-бота компании DeepSeek. И это явилось прекрасным прикрытием реальных причин временного, но ощутимого снижения цены акций «Nvidia» с возможностью под шумок неплохо заработать.
БИОМАССА ДЛЯ ПОДПИТКИ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Говоря о тех плюсах, который даёт рядовому пользователю искусственный интеллект, российские пользователи, в частности, замечают: «Настоящее сокровище ИИ — это не пользовательский интерфейс или модель (они стали товарами). Истинная ценность заключается в данных и метаданных, том „кислороде“, которые питает потенциал ИИ. Будущие богатства — в наших данных».
Так оно и есть!
Рассуждая о причинах успеха китайских разработчиков искусственного интеллекта, необходимо напомнить очевидную (хотя очевидную не для всех) вещь. Информация — это и в самом деле питательная масса для развития ИИ.
Очевидно, что с начала 1990-х годов и как минимум до конца 2010-х шло глубокое накопление и переработка того, что уже не первый год называется Big Data – большие данные. Сегодня очевидно, что в этой деятельности немалых успехов достигла американская компания Google. Впрочем, она была далеко не единственной.
В эти десятилетия для формирования и наполнения базы Big Data производилась тотальная оцифровка рукописей, книг, газет, аудио- и видео-записей и т.д.
После тотального введения банковских карт (на Западе это случилось раньше, чем в РФ) производился анализ всех трансакций. Всё делалось для того, чтобы через некоторое время подключить к Big Data ИИ.
Таким образом, фундамент, на котором базируется сегодня ИИ — это Big Data. Для постоянной подпитки этого технологического дуэта в течение последних 20-30 последних лет, активно создавались и раскручивались разного рода социальные сети и мессенджеры. Сегодня это — биомасса ИИ, его питательный бульон, с очень глубокой обратной связью.
При этом нельзя забывать, что с одной стороны находится аналоговый механизм (то есть человек), а с другой — цифровой механизм. Здесь принципиально разные скорости обработки данных. В отличие от человека, скорость работы ИИ куда быстрее, и это является фундаментальной основой ИИ, его неоспоримым преимуществом.
Это — так сказать, краткое историко-теоретическое напоминание о сути происходящих сегодня процессов. А как это реализовывалось? Два примера.
В ЧЁМ ПРИЧИНЫ КИТАЙСКОГО УСПЕХА?
22 января 2025 года президент США Дональд Трамп заявляет о запуске компании Stargate, цель которой — развитие инфраструктуры ИИ. Было также сказано, что три компании (OpenAI, SoftBank и Oracle) «вложат в проект $100 млрд., а в ближайшие годы инвестции увеличатся до $500 млрд.».
По мысли Трампа, Stargate станет «крупнейшим проектом инфраструктуры ИИ в истории». В рамках его реализации будет построена «физическая и виртуальная инфраструктура для поддержки следующего поколения ИИ», включая центры обработки данных по всей территории США. Первый объект по обработке данных уже строится в Техасе.

Не надо иметь семь пядей во лбу, чтобы понять: запуск программы Stargate однозначно связан с осознанием очевидного факта — Соединённые Штаты отстают от того же Китая в разработке ИИ. Безусловно, успехи американских разработчиков в этом деле огромны. Но американцы, как известно, к тому большие мастера блефа и денег. А в КНР на деле (на примере разработок той же компании DeepSeek) доказали: китайский искусственный интеллект может быть и лучше, и дешевле, чем американский.
Попутное пояснение. Американцы — большие любители символических «совпадений». Дело в том, что с 1972 и примерно до 1985 года на базе Стэнфордского университета уже работала программа с точно таким же названием — Stargate («Звёздные врата», есть и другие данные, что окончательно её прикрыли только в 1995 году). Программа была разработана для нужд ЦРУ и Разведывательного управления Пентагона (РУМО). Знаете, чему была посвящена программа? Дистанционному наблюдению. Проще говоря, возможности читать мысли на расстоянии. Причём, в разработке программы принимали такие известные в своё время медиумы и экстрасенсы, как Джозеф МакМонигл, Пэт Прайс, Инго Сванн, Ури Геллер. Но это так, заметки на полях.
Важное обстоятельство: разработки в сфере ИИ (кстати, не только в этом направлении) в Китае уже не первый год ведутся не просто под опекой Министерства промышленности и информатизации КНР, но и при его непосредственном участии и самой активной помощи. Так же, как в предыдущие годы шли работы по созданию китайской Big Data.
Очевидно и то, что столь масштабные проекты, как разработки в области создания искусственного интеллекта не могут быть полноценно реализованы без участия государства. Похоже, теперь это дошло и до руководства Соединённых Штатов в его новой реинкарнации…
СПРАВКА
Для тех, кого озадачил заголовок текста, поясняем.
Дикпик* (dick pick) — разновидность эксгибиционизма или даже сексуального домогательства, получившее широкое распространение в начале 2010-х годов. Связывается с цифровизацией мирового информационного пространства и популяризацией социальных сетей.
В буквальном смысле означает отправку абоненту (чаще всего — абоненту женского пола) фотофайла с изображением мужского полового органа.
*«Ригель» не уверен точно, запретил ли Роскомнадзор это явление, но на всякий случай извещает: дикпик может являться запрещённым в России. Какая мерзость!





Комментарии: